


Тепер, коли будь-хто може використовувати штучний інтелект для генерації ключових слів і розгортання платної пошукової кампанії за лічені хвилини, легко припустити, що важку роботу зроблено.
Але створення структурованої, масштабованої продуктивності все ще вимагає справжнього розуміння того, як працює пошук.
Такі методи, як n-грами, відстань Левенштейна та подібність Жаккара, дають пошуковим маркетологам можливість інтерпретувати заплутані дані пошукових термінів, застосовувати контекст клієнта та створювати надійні структури, які штучний інтелект не може створити сам по собі. Ось як.
Що показують n-грами в аналізі PPC і SEO
Подумайте про n-грами як про «n» слів, які складають ключове слово. Наприклад, у терміні «приватний доглядач поблизу» ми маємо:
- 3 уніграми (одне слово): «приватний», «охоронець» і «поруч»
- 2 біграми (два слова підряд): «приватний доглядач» і «доглядальник поруч»
- 1 триграма (три слова підряд): «приватний доглядач поруч»
N-грами корисні для спрощення списків ключових слів.
Цього тижня я змінив структуру кількох кампаній із понад 100 000 пошукових термінів. Використовуючи n-грами, я зміг скоротити ці списки до:
- ~6000 уніграм.
- ~23 000 біграмів.
- ~27 000 триграмм.
З цими меншими наборами ви можете виявити, що всі ключові слова, які містять уніграму «безкоштовно», мають низьку ефективність, тому ви виключите «безкоштовно» як мінус-слово із широкою відповідністю.
Навпаки, ви можете побачити, що «поруч» працює надзвичайно добре, спонукаючи вас експериментувати з місцевими варіантами та цільовими сторінками.
Однак існують чіткі обмеження:
- Вам потрібен великий обсяг пошукових термінів, тому цей метод більше підходить для великих бюджетів.
- Чим більше ваше «n», тим менш корисним стає метод, оскільки він дає більші результати, що перешкоджає меті. На цьому етапі вам знадобляться більш просунуті методи, такі як відстань Левенштейна або подібність Жаккара.
Кластеризація ключових слів за допомогою n-грам
Аналіз даних SEO та PPC часто вимагає перегляду величезних обсягів довготривалих пошукових термінів, багато з яких з’являються лише один раз і містять дуже мало даних.
n-грами допомагають перетворити ці хаотичні дані з довгим хвостом у чіткі, керовані інтелектуальні дані.
Це дозволяє скоротити марні витрати, виявити нові можливості та побудувати масштабовану структуру.
- Почніть з експорту даних пошукових термінів. У PPC сюди входять вартість, покази, кліки, конверсії та цінність конверсії, розподілені за пошуковим терміном.
- Для кожного n-грама, сума вартості, показів, кліків, конверсій і цінності конверсії.
- Потім обчисліть CPA, ROAS, CTR, CVR та інші відповідні показники.
За допомогою цього коротшого, легше засвоюваного набору даних ви можете ранжувати найвитраченіші n-грами, які не конвертуються (ваші мінуси), і ті, які перетворюються (ваші позитивні).
Звідти створюйте групи оголошень навколо повторюваних n-грамів, які підвищують ефективність.
Наприклад, ви можете виявити, що n-грами, пов’язані з надзвичайними ситуаціями («24/7», «у той самий день», «терміново» тощо), часто забезпечують вищі коефіцієнти конверсії. Ви б сегментували їх, щоб контролювати їх ефективніше.
Підсумок: n-грами допомагають виділити теми, які заслуговують на особливу увагу.
Після ідентифікації стає набагато легше створювати розширені платні пошукові структури, зосереджені на високоефективних n-грамах, і генерувати сильнішу рентабельність інвестицій.
Копайте глибше: як виявити приховані перлини у ваших облікових записах платного пошуку
Як використовувати відстань Левенштейна для покращення якості ключових слів
Відстань Левенштейна кількісно визначає мінімальну кількість редагувань одного символу – вставок, видалень або замін – необхідних для перетворення одного рядка в інший.
Це може здатися складним, але насправді концепція проста.
Відстань Левенштейна між «кішкою» та «котиками» дорівнює 1, тому що вам потрібно додати лише «s». Між «кішкою» і «собакою» відстань 3. І так далі.
Типовим випадком використання є виявлення орфографічних помилок бренду та конкурента, які з’являються у ваших пошукових термінах.
Наприклад, «uber» і «uver» мають відстань Левенштейна 1, тому ви з упевненістю виключили б неправильно написану версію зі своїх небрендових кампаній.
Ви можете застосувати ту саму логіку до релевантності ключового слова.
Якщо відстань між ключовим словом і пошуковими термінами, яким воно відповідає, занадто велика (придумайте 10 або більше), ці терміни, ймовірно, мають мало спільного з ключовим словом і заслуговують на перегляд.
З іншого боку, низька відстань зазвичай означає, що ці запити безпечні та не потребують ручної перевірки.
Консолідація ключових слів КПП дистанцією Левенштейна
Після використання n-грамів для створення початкових кластерів ключових слів у вас все одно можуть залишитися тисячі пошукових термінів для організації в працездатну структуру кампанії.
Сортувати 6000 уніграм вручну не можна. Тут дистанція Левенштейна стає важливою.
Мета полягає в тому, щоб об’єднати групи оголошень, націлені на майже ідентичні ключові слова, щоб уникнути надто гранульованої структури, подібної до SKAG.
Занадто велика деталізація створює складні звіти та керування обліковим записом, а також неефективне призначення ставок і марні витрати.
Використовуючи той самий набір даних, обчисліть відстань Левенштейна між запитами в різних групах оголошень.
Потім визначте найближче ключове слово та групу оголошень, використовуючи попередньо визначене порогове значення – наприклад, 3 для високої точності.
Це дає змогу безпечно об’єднувати ключові слова та групи оголошень. З меншим порогом, наприклад 6, ви також можете групувати або називати групи оголошень за схожістю чи наміром.
Ось простий приклад, який демонструє, чому три ключові слова нижче можна згрупувати разом:
| Відстань Левенштейна | Сантехнік 24/7 | 24 7 сантехнік | 247 сантехнік |
| Сантехнік 24/7 | 0 | 1 | 1 |
| 24 7 сантехнік | 1 | 0 | 1 |
| 247 сантехнік | 1 | 1 | 0 |
Копайте глибше: як використовувати мінус-слова в PPC для максимального націлювання та оптимізації витрат на рекламу
Йдемо далі з подібністю Жаккара
У PPC ви можете спростити подібність Jaccard як проксі, щоб зрозуміти перекриття між двома наборами n-грамів.
Розрахунок простий: кількість спільних уніграм між двома наборами поділена на загальну кількість унікальних уніграм в обох наборах.
Це може здатися технічним, але це легко уявити. Подумайте про це як:
- Подібність Jaccard = червоний / зелений
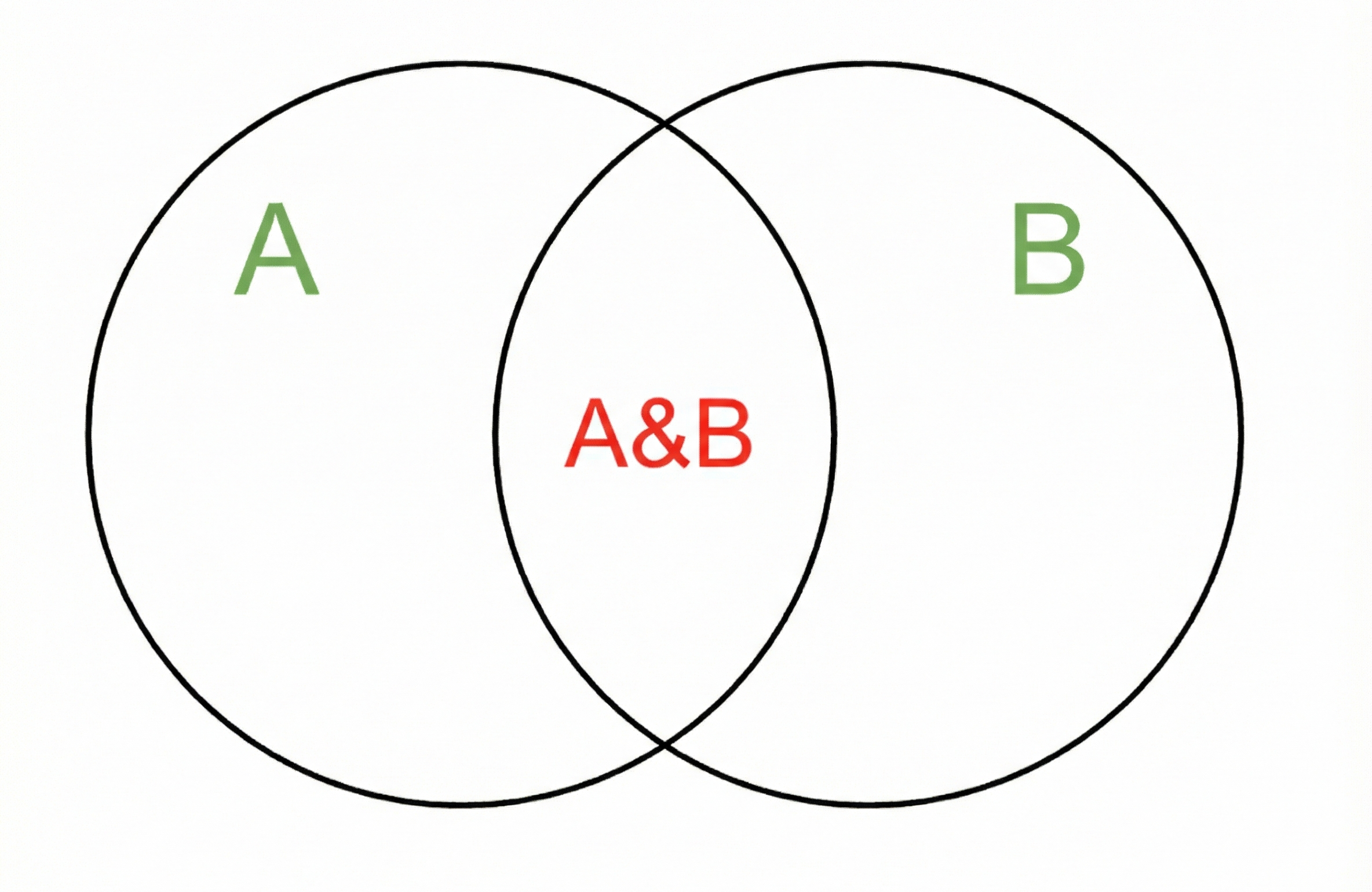
Ось конкретні приклади:
- «сантехнік Нью-Йорк» і «сантехнік Нью-Йорк» = 1 (всі три уніграми з’являються в обох наборах, тільки в іншому порядку)
- «сантехнік Нью-Йорка» та «сантехнік Нью-Йорка» = 0,25 (спільно використовується лише «сантехнік», а всього чотири уніграми)
Подібність Jaccard є корисним першим кроком для дедуплікації подібних ключових слів. По суті, він усуває розрив між старою фразовою відповідністю та модифікованою логікою широкої відповідності.
Але він також має обмеження, оскільки не враховує значення.
У наведеному вище прикладі «нью-йорк» і «Нью-Йорк» слід визнати еквівалентними, але підрахунок Jaccard розглядає їх як різні.
Щоб впоратися з таким рівнем нюансів, вам потрібні більш просунуті методи (про які я розповім у наступній статті).
Поєднання подібності Жаккара та відстані Левенштейна
Розглянемо кампанію курсу з кібербезпеки з наступними 10 ключовими словами:
| Ключове слово | Середня кількість пошукових запитів Semrush за місяць у США |
| курси з кібербезпеки | 5400 |
| онлайн-курс з кібербезпеки | 1900 |
| безкоштовні курси з кібербезпеки | 1300 |
| онлайн-курси з кібербезпеки | 1300 |
| курс кібербезпеки | 1000 |
| курси з кібербезпеки онлайн | 880 |
| курс кібербезпеки Google | 880 |
| безкоштовні курси з кібербезпеки | 720 |
| безкоштовні курси з кібербезпеки | 590 |
| онлайн-курси з кібербезпеки | 480 |
Комбінуючи версії множини й однини, а також перевпорядковані версії цих ключових слів, ви можете скоротити 10 найпопулярніших у четвірку з більш ефективними:
- «Курси кібербезпеки».
- «Онлайн-курси з кібербезпеки».
- «Безкоштовні курси з кібербезпеки».
- «Курс кібербезпеки Google».
Ви можете використовувати для цього n-грами, але масштабування аналізу n-грамів за тисячами ключових слів може виявитися непосильним.
Більш ефективним підходом є використання обох показників подібності послідовно.
- Спочатку застосуйте відстань Левенштейна, щоб консолідувати дуже подібні запити.
- Потім використовуйте подібність Jaccard, щоб дедуплікати переупорядковані варіанти.
- На кожному кроці ви підсумовуватимете звичайні ключові показники ефективності (вартість, конверсії та інші показники), щоб аналіз n-грам залишався ефективним.
Результатом є чітка, стиснута структура, яка зберігається, навіть коли обсяг пошукового терміну зростає.
Реструктуризація платних пошукових кампаній із передовими семантичними техніками
За допомогою правильних семантичних прийомів ви можете швидко реструктурувати масивні набори ключових слів із послідовними високоякісними результатами.
Штучний інтелект може абсолютно допомогти, надавши початкове резюме, але ви не повинні повністю покладатися на нього.
В іншому випадку це класичний випадок «сміття входить, сміття виходить».
Широка відповідність може бути потужною, але вона також створює більше шуму. Ці методи допоможуть вам перевірити, чи ваші запити залишаються на правильному шляху.
Використовуйте n-грами, відстань Левенштейна та подібність Жаккара, щоб застосувати контекст клієнта до необроблених даних пошуку та створити стабільну структуру, яка відповідає цілям вашої кампанії.
Спочатку це може здатися приголомшливим, тому ось підсумкова таблиця, щоб завершити статтю:
| Сценарій | Найкраща техніка | чому |
| Визначте шаблони високого наміру у величезному експорті пошукових термінів | n-грами | Швидко відкриває теми; зменшує розмірність |
| Очистіть повторювані або майже повторювані ключові слова в масштабі | Відстань Левенштейна | Фіксує орфографію + структурну схожість |
| Дедуплікуйте рядки ключових слів зі зміненим порядком або дещо зміненими | Подібність Жаккарда | Порівняння на основі токенів без урахування порядку |
| Створюйте масштабовані кластери для перебудови кампаній | Комбо: Левенштейн → Жаккар → n-грам | Послідовність дає точність + стиснення |
Авторів, які вносять свій внесок, запрошують створити вміст для Search Engine Land і обирають за їхній досвід і внесок у пошукову спільноту. Наші дописувачі працюють під наглядом редакції, і внески перевіряються на якість і актуальність для наших читачів. Search Engine Land належить Semrush. Автора не просили прямо чи непрямо згадувати Семруша. Думки, які вони висловлюють, є їхніми власними.


