

 Трохи більше двох місяців після того, як World World висвітлював дебют експериментального Gemini 2.5 Pro, компанія оголосила про значне оновлення після попереднього оновлення до моделі, яка викликала змішані реакції розробників.
Трохи більше двох місяців після того, як World World висвітлював дебют експериментального Gemini 2.5 Pro, компанія оголосила про значне оновлення після попереднього оновлення до моделі, яка викликала змішані реакції розробників.
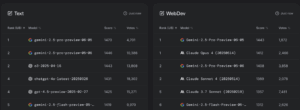
Останній Gemini 2.5 Pro Gemini 2.5 підскочив на вершину рейтингу продуктивності AI з оцінкою ELO 1470, рейтинговою системою шахового стилю, яка вимірює, як часто моделі б'ють один одного у порівнянні голови до голови на основі відгуків користувачів. 24-кратний стрибок ELO затвердить лідерство Близнюків на Lmarena, широко переглянутому лідерській дошці AI, навіть оскільки це коштує всього 1,25 долара за мільйон вхідних жетонів порівняно з O3 Openai за 10,00 доларів. Різниця в цінах ще більша при порівнянні з Claude Opus 4, вартістю одного дванадцятого для вхідних жетонів.
Хоча великі мовні моделі набирають грунт особливо швидко в розробці веб -сайтів, вони також досягають успіху в науці. Останні показники моделі Gemini 2.5 86,4% на GPQA Diamond Бентечко, важкий тест наукових знань на рівні випускників, де він перевершує O3 (83,3%) OpenAI (83,3%) та Claude Opus 4 (79,6%) в оцінках по одному з них. З точки зору редагування коду, він веде пакет Допоможіть поліглоту з рахунком 82,2%.
З лідера Lmarena:
Оголошуючи оновлення, Google підкреслив, що ця версія стосується попередньої критики, позиціонувавши модель для більш широкого комерційного використання. “Ми також розглянули відгуки від нашого попереднього випуску 2.5 Pro, вдосконалюючи його стиль та структуру-це може бути більш креативним з кращого форматуваного відповіді”,-написав Тульсі Доші, старший директор, управління продуктами в Google Deepmind. Доші описує оновлену модель як “нашу найрозумнішу модель досі” і зазначає, що “буде загальноприйнята, стабільна версія, що починається через пару тижнів, готова до додатків для підприємств”.


